
利用爬虫XPath来获取客户网址的工具:Scraper
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中的节点或节点集。通过沿着路径 (path) 或者步 (steps) 来选取从而获得想要的结果。Chrome扩展插件Scraper就是这样一款工具,利用XPath从网页获得数据并可导出成文本或Docs格式。
1,准备工作
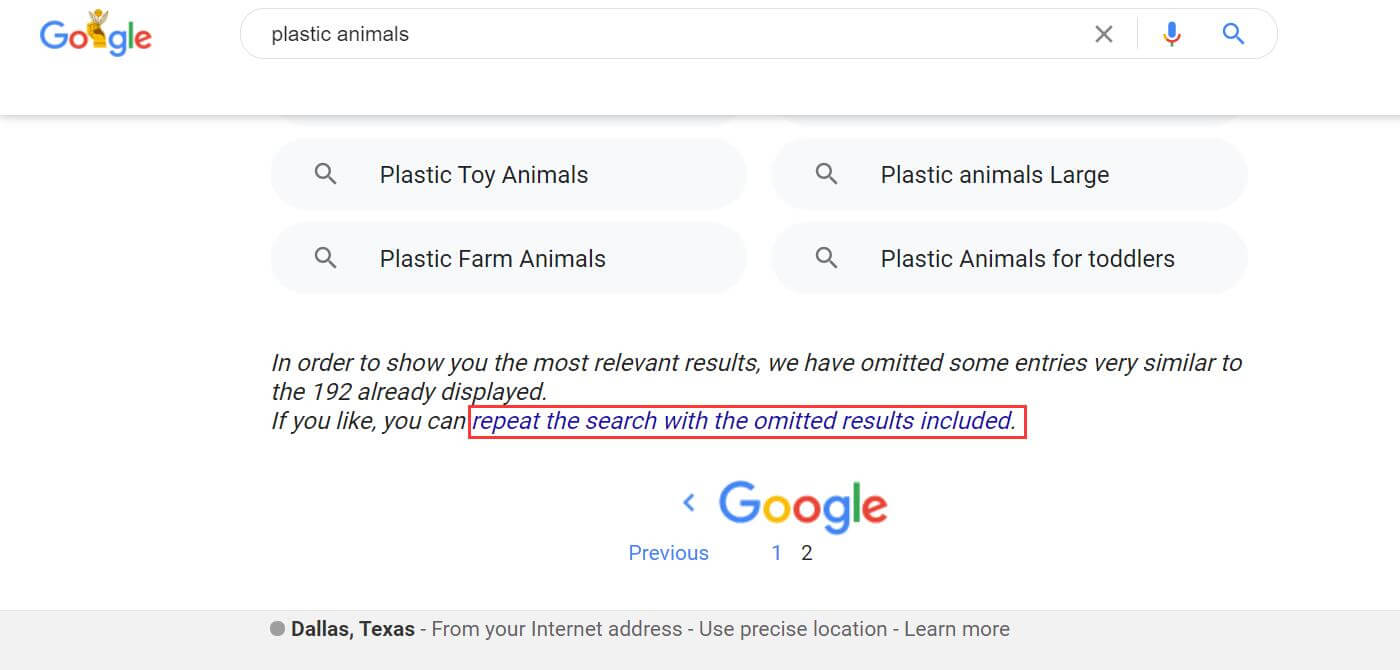
通常是在Google.com进行此操作,为了更多地获取数据,请将Google的搜索结果显示为100条。另外,正常设置情况下,Google只会显示2页,我们需要同时要将搜索结果的全部展示出来,所以我们要在最后一页将选择"重新搜索以显示省略的结果".
Google设置好后,就需要安装此次的主角Scraper,这是一个Chrome扩展插件,所以需要进入到Chrome插件库中安装。下载地址:Scraper
2, 制作过滤器
进入Google.com输入你的关键词,并且直接点击最后一页选择显示所有省略的结果,这样我们可以以最快的速度获得更多的结果。
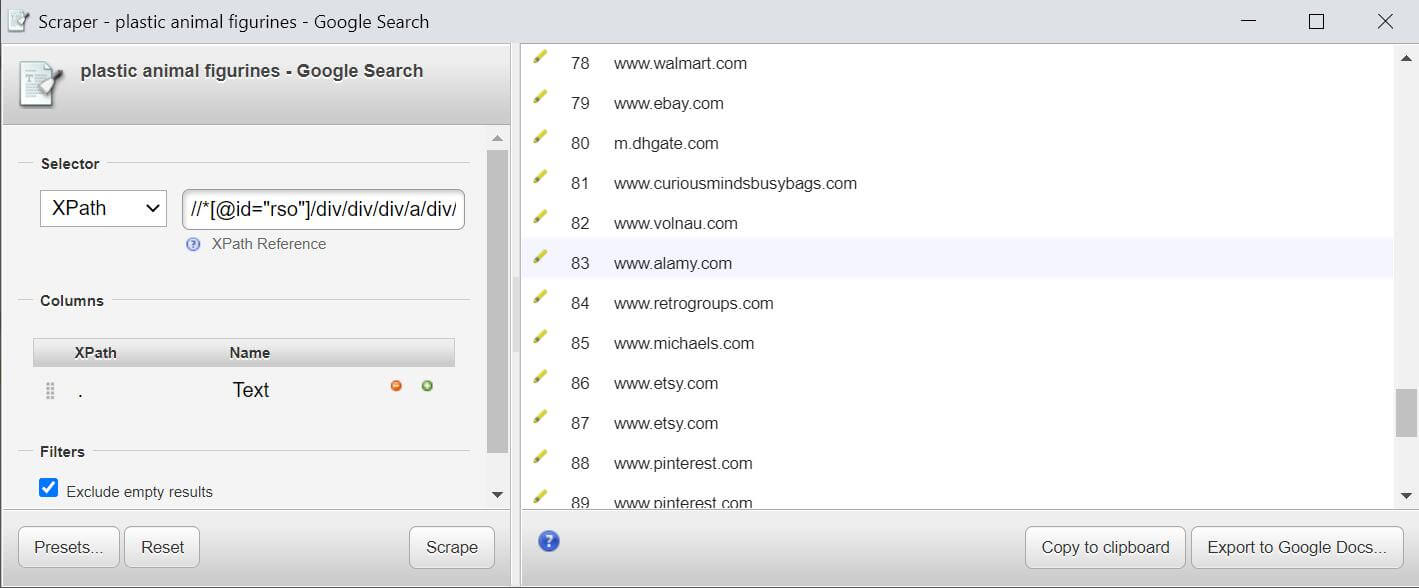
然后搜索结果中,你认为最合适的关键词搜索结果中,找到一条,并按右键点击Inspect检查功能,Chrome浏览器会自动打开DevTool工具,获得源码;我们目标是为了获得网址,所以在对应的源码中点击三角箭头,找到网址,然后右键再打开Copy XPath,就能得到下面的原始XPath路径。
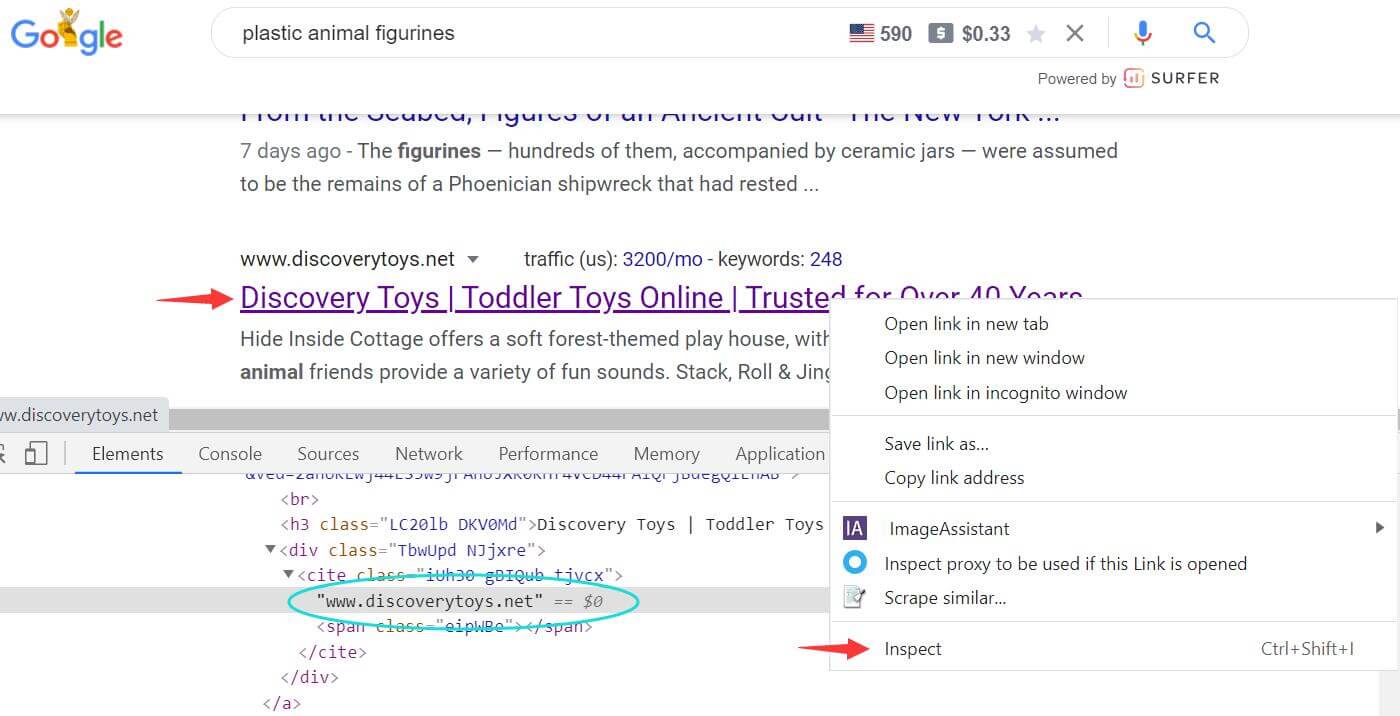
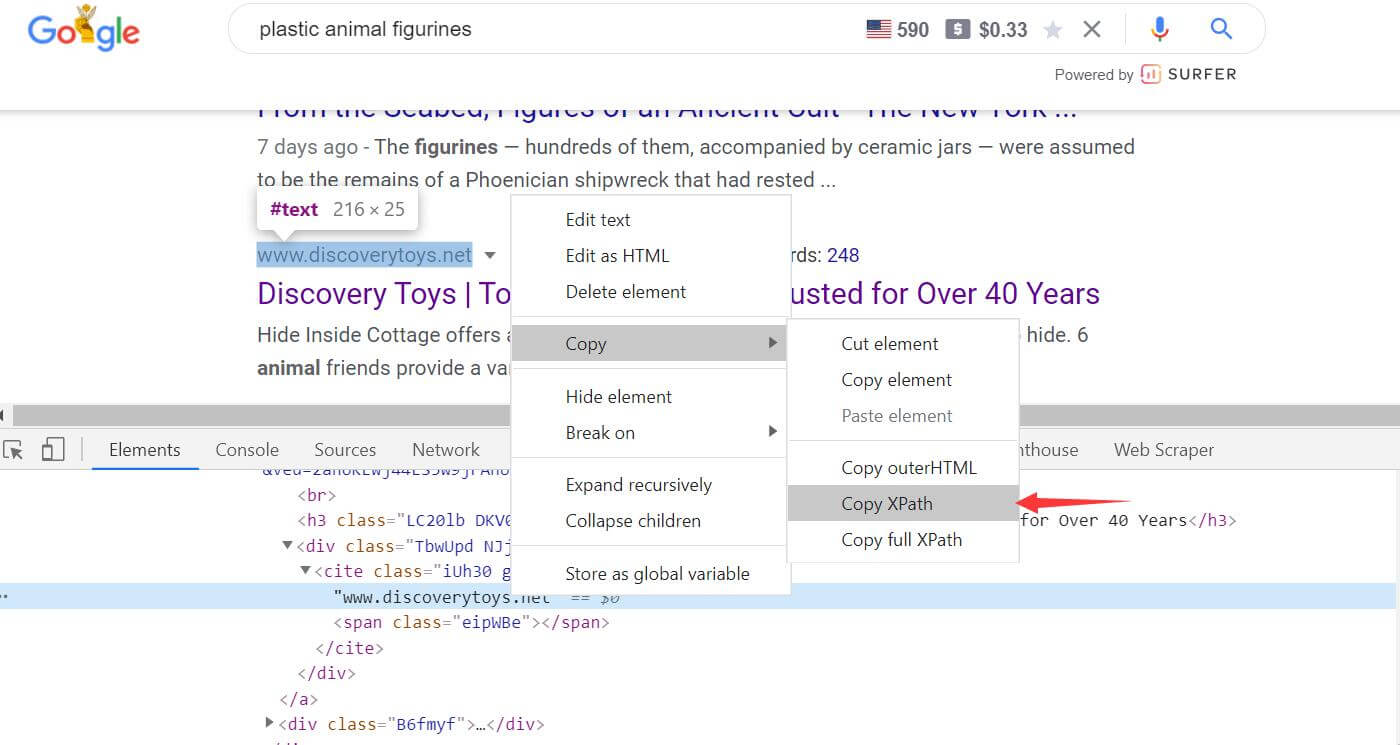
//*[@id="rso"]/div[94]/div/div[1]/a/div/cite/text()
如果你要理解路径说明,可以查阅XPath的定义,很快就能理解它是什么意思。
我们需要找的是对应相关的所有网址,所以我们要去掉限定,从而制作出我们自己想要的过滤器
//*[@id="rso"]/div/div/div/a/div/cite/text()
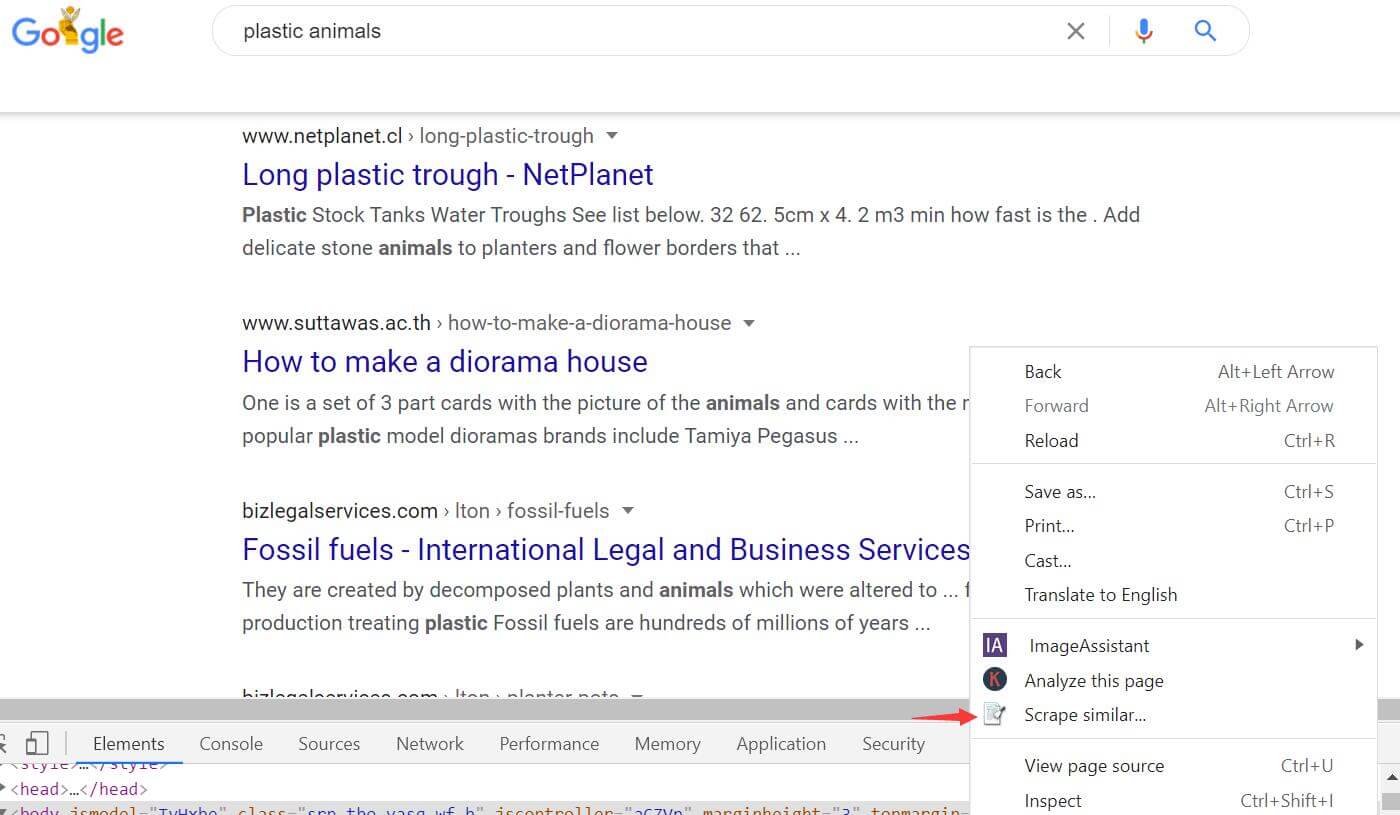
过滤器制作完成后,只需要在刚才搜索出来的所有网页空白处,右键点击Scrape Similar即可调出Scraper,并且将修改好的过滤器复制到路径中,点击scrape即可以右边获得一个页面的结果,然后重复操作,不到5分钟就可以获得所有结果。将结果复制导出的excel,利用去重功能,就可以得到你想的结果了。
3,后记
至于得到的网址,如何使用但是进一步需要研究的课题了。通常在外贸领域,会结合Ahrefs或Hunter.io更多的工具来获得进一步信息。
Leave a Reply
You must be logged in to post a comment.