
pyTranscriber将语音自动识别成文字或字幕
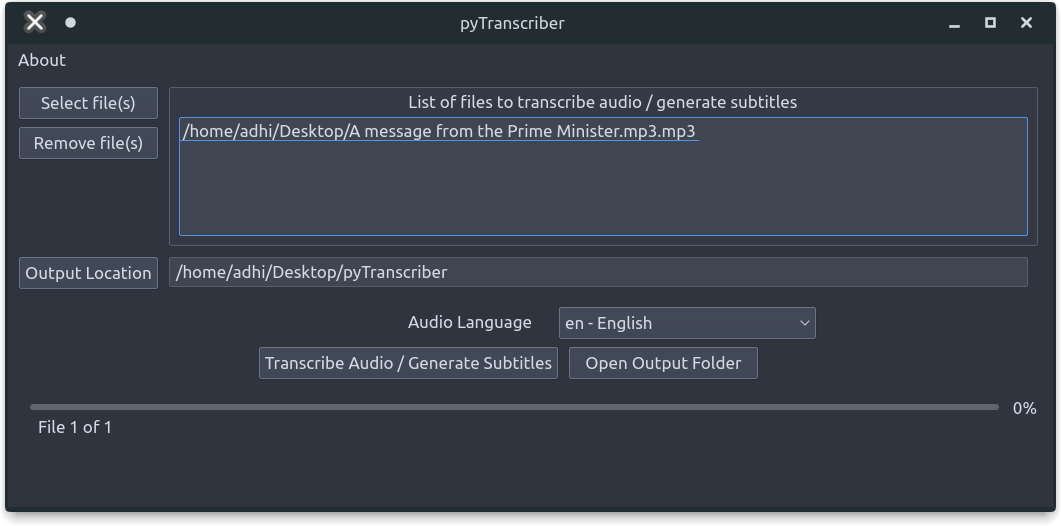
pyTranscriber是一个应用程序,可用于通过直观的图形用户界面为音频/视频文件生成自动转录/自动字幕。语音识别是由谷歌语音识别应用编程接口使用Autosub完成的。pyTranscriber支持兼容安装在Windows/Linux/MacOS三种平台上。
pyTranscriber是作者JAutosub (Java)项目的改进版本,创建它的原因是在一个项目中混合这两种不同的语言,会存在一定的局限性、产生一些预想不到的问题。
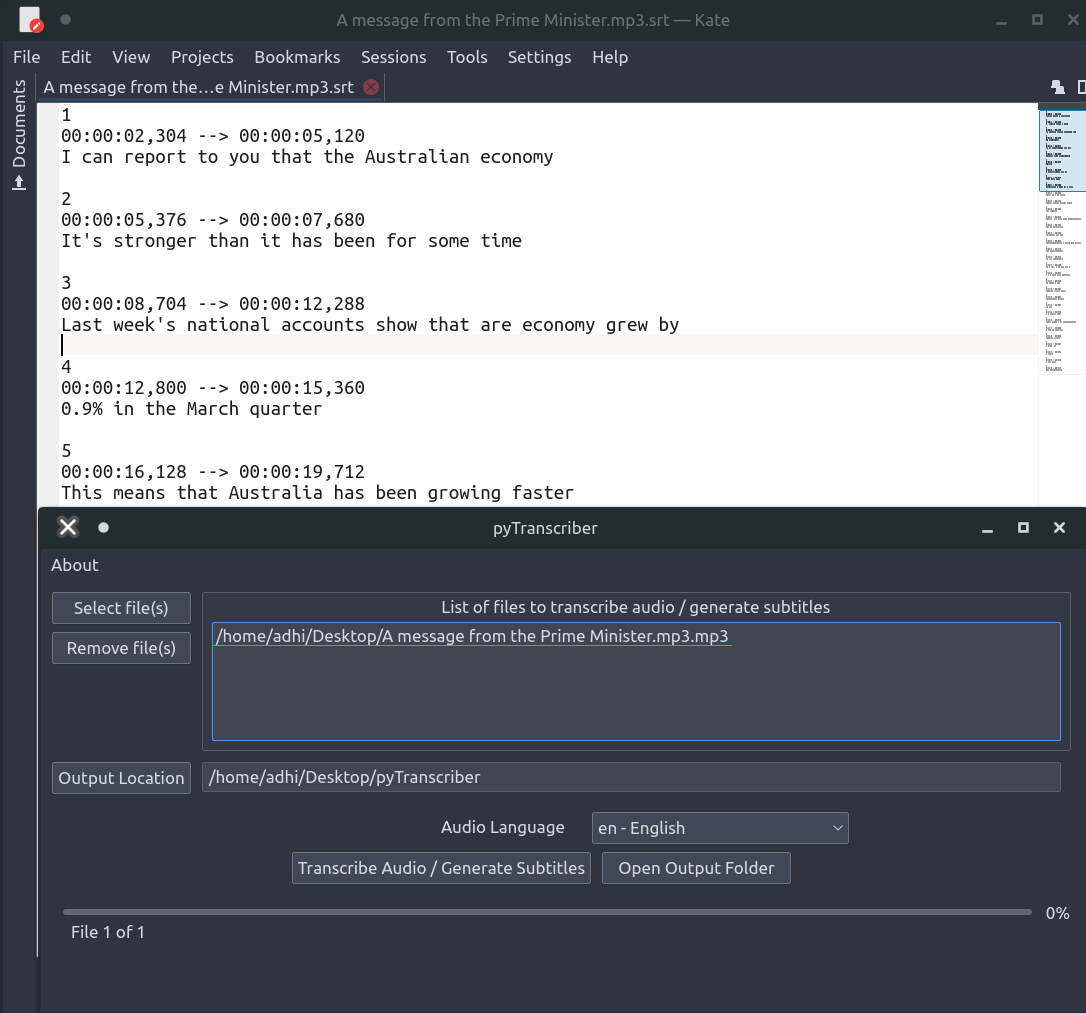
默认情况下,该应用程序将音频转出为字幕srt和文字txt文件。SRT文件可以使用Aegisub进行编辑。但它需要接入互联网,因为它使用谷歌云语音服务器进行工作,就像Youtube自动字幕一样。
重要提示:由于语音识别技术仍不完全准确,因此结果的准确性可能会有很大差异,这取决于许多因素,主要是音频的质量/清晰度。理想情况下,音频输入不应有背景噪音、音效或音乐。如果只有一个说话者,并且他说话的速度清晰而缓慢,那么识别就更加准确。有时,在理想/幸运的条件下,有可能获得接近95%的准确度结果。
Leave a Reply
You must be logged in to post a comment.